Survey Biases Due To Sampling Frame Coverage Problems
In a previous article, we discussed the use of the Internet as a survey mode. The main point of that article is that the Internet is useful only to the extent that the target survey estimate has about the same value among the Internet users as well as the non-Internet users. In that case, the Internet population can act as a cheap, efficient and accurate way of conducting surveys. In another article, we discussed the use of telephones to conduct surveys in Argentina. Again, we came to the similar conclusion that telephone is useful only to the extent that the target survey estimate has about the same value among the telephone and non-telephone populations.
In the United States, it is acceptable to use the telephone to conduct surveys. This is because the penetration of telephone within the United States is almost universal, whereas it was only about two-thirds in Argentina. We can formally quantify the magnitude of the survey estimate bias as follows:
Suppose that the incidence of telephone ownership is 95% among the population, and suppose the survey estimate has a value of 50% among persons in telephone households.
Let X% = survey estimate among the non-telephone households.
Then the true survey estimate = (0.95 x 50%) + (0.05 x X%) = 47.5% + (0.05 x X%)
The bias is the difference between the true value and the telephone-only value = 47.5% + (0.05 x X%) - 50% = (0.05 x X%) - 2.5%
If X is 0%, then the bias = -2.5%, which is the minimum value
If X is 50%, then the bias = 0.0%
If X is 100%, then the bias = 2.5%, which is the maximum valueSuppose that the incidence of Internet ownership is 60% among the population, and suppose the survey estimate has a value of 50% among persons among Internet users.
Let X% = survey estimate among the non-Internet users
Then the true survey estimate = (0.60 x 50%) + (0.40 x X%) = 30% + (0.40 x X%)
The bias is the difference between the true value and Internet-only value = 30% + (0.40 x X%) - 50% = (0.40 x X%) - 20%
If X is 0%, then the bias = -20%, which is the minimum value
If X is 50%, then the bias = 0.0%
If X is 100%, then the bias = 20%, which is the maximum value
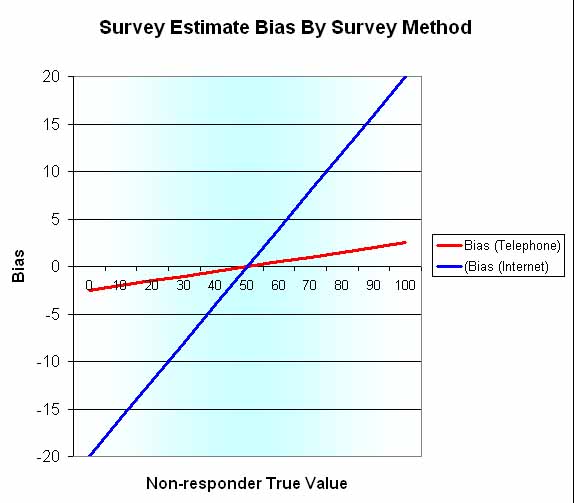
In the following chart, we have plotted the survey estimate bias as a function of the value of the non-responder true value for the two methods. In this situation, the telephone mode is acceptable because the bias is bounded between plus or minus 2.5% when the true value is 50%.. But the Internet mode is risky because the bias is bounded between plus or minus 20%.
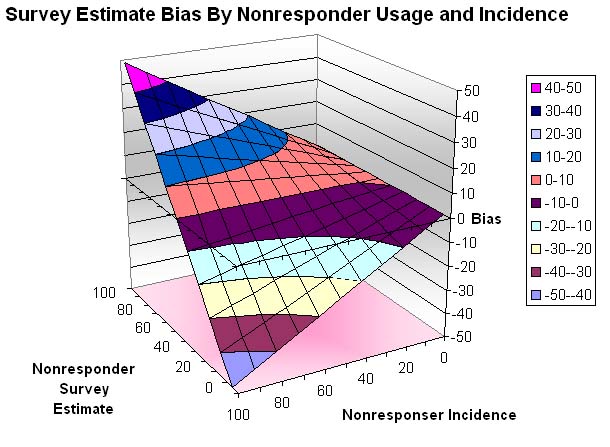
The chart above is restricted to two sets of survey nonresponder incidences (5% for non-telephone owners and 40% for non-Internet users). The chart can be generalized to a two-dimension surface chart for arbitrary nonresponder incidences as shown below. The preceding chart just shows the two cross-sections of this surface at nonresponder incidences of 5% and 40% respectively. The important thing to note here is that when the nonresponder incidence is high, then the outcome is virtually totally determined by the nonresponder survey estimate. In that case, the devastating truth is that no information is forthcoming from the nonresponders by definition, and it becomes a test of faith to use the data from the responders only.
We bring out that last point because it has great relevance to web-based surveys. We have so far assumed that the Internet incidence is something like 60%, but the practical realities of drawing an Internet sample may mean that the actual coverage is significantly less. In fact, it may be surprising to finding that the nonresponder incidence is close to 100%! We explain this attrition process in terms of a number of steps:
In the beginning, there was the target population (e.g. all adults living in the United States).
If we decide to conduct a web survey, then we have an operational population that is defined as the population of all web users within the target population. We have just lost all non-web users. This is the first level of attrition. The survey estimate bias as described above now applies.
But we are assuming that we have a frame (or listing) of the operational population in order for us to draw a sample. Such a frame of all Internet users does not exist, nor is it likely to exist. Instead, what exists are various lists of email addresses that are available from list compilers. These lists are incomplete, as the unduplicated total of all such lists appears to fall far short of the estimated total number of Internet users. For example, the frame is based upon 13 million names when the Internet population is estimated to be 130 million persons. This is the second level of attrition to the coverage.
Suppose we draw a random sample from the compiled email addresses to solicit survey participation. When email addresses go out, some will be bounced back as being undeliverable. This could be a discontinued account, or an error in entering the information onto web forms, or a fictitious account, and so on. This is the third level of attrition to the coverage.
Some email servers are set up to absorb non-working addresses without returning an undeliverability message. Thus, it is like as if the email went into a black hole, even though the target is non-existent. This is the fourth level of attrition to the coverage.
Some people have multiple email addresses. For example, the author of this article has five working email addresses for different purposes. Without further information, these multiple email addresses will look like different people. Therefore, the sampling frame is in fact smaller than it seems. This is the fifth level of attrition to the coverage.
Of those who receive the email delivered to their mailboxes, some will have very strong filters to eliminate spam, which the solicitation for survey participation would likely belong. These people will never even see this particular email. This is the sixth level of attrition to the coverage.
Of those who received the email and actually read the email message, some of them will decline to respond for various reasons (e.g. not enough time, concern about privacy, not interested in the subject, averse to taking surveys, etc). This is the seventh level of attrition to the coverage.
Of those who received the email and actually read the email, some of them will respond by clicking onto the web survey. Of these, some of them will be unable to complete the survey (e.g. took too much time, got confused, the browser was incompatible, lost interest, disliked the questions, etc). This will be a function of the survey design, length and subject matter. This is the eighth level of attrition.
Finally, many web surveys are conducted on pre-recruited Internet panels, all in the name of convenience, timeliness and high 'response rate'. But this requires a set of people who are willing to undergo the survey process repeatedly, and not everyone will agree to do so. This is the ninth level of attrition.
We started considering the simple case of the first level of attrition. When we consider all the levels of attrition that must happen in practice, we must surely be closer to the case of a very low responder incidence. It would not be so bad if the attrition were random, but most of these attritions occur as a result of self-selection (that is, the nonresponders excluded themselves based upon some rational thinking). According to the graph, the true survey estimate will in fact be nearly completely determined by the nonresponders, about whom we have no information whatsoever from the web survey. This is the ugly reality of web-based surveys.
Much of the time, the sellers of web-based surveys will claim that they have respresentative samples. Do you believe that the net residual of these levels of attrition will lead to representative samples? They will also say that they have demographically representative samples. Well, I can go down to the street corner and get you 100 interviews, of which 52 are female and 48 are male as in the adult population, but that doesn't mean that this sample is representative of the population of this country. In fact, I know that it only represents people who pass through that street corner at this time of day and who are willing to waste some time by speaking with me.
(posted by Roland Soong, 9/8/2004)
(Return to Zona Latina's Home Page)