(source: 2002 MARS study)
Using the Internet as a Survey Tool
The internet is a two-way interactive medium. As such, it has the potential of being used as a survey instrument. This is particularly significant at a time when other survey modes (such as face-to-face personal interviews, mail and telephone) are confronting declining cooperation rates in these changing times (e.g. security concerns, inundation of unsolicited mail, aggressive telemarketing, unlisted telephone calls, answering machines, caller ID, opt-out listings, etc).
The internet is obviously the logical survey tool for the universe of all internet users. But what is the validity of extrapolating the results of internet surveys to the non-internet universe? That depends on the characteristics and behavior of the internet users. Now, a great deal is known about the characteristics of internet users vis-ŕ-vis the general population. There are many data sources that document the internet population, and we will cite some survey results from the 2002 MARS study. This is a mail survey of adults 18+ in the 50 states of the USA conducted during the first quarter of 2002. Within that study, 59.5% of the respondents indicated that they had used the Internet in the last 30 days.
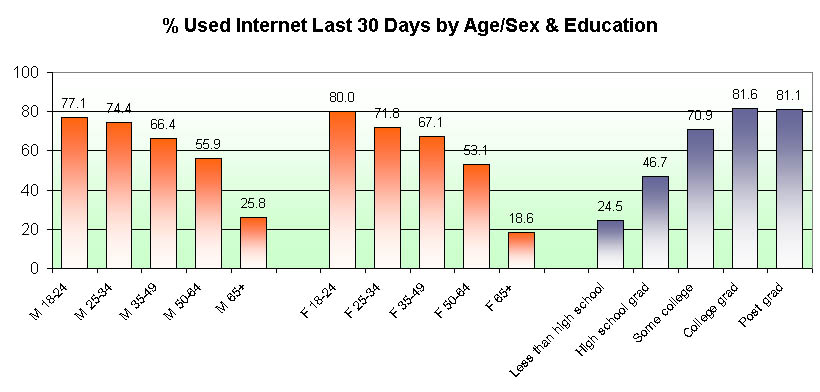
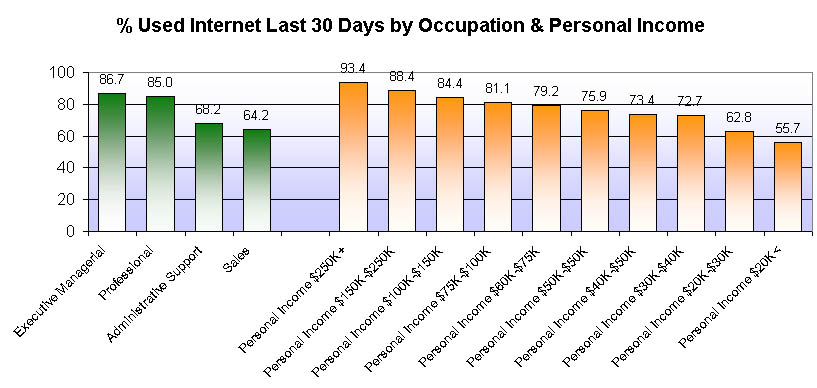
In the next two charts, we show the incidence of internet users separately by age/sex groups, educational level, occupation and personal income (among those who are employed).
(source: 2002 MARS study)
(source: 2002 MARS study)
These charts support the common belief that the internet population is younger, better educated, hold better jobs and are better paid. Therefore, any simple sample of the internet population will not be directly representative of the general population. That much is not in dispute. But we are not writing this article to argue this point. Rather, we wish to discuss the issue of whether it is possible to conduct an internet survey, weight that sample to the general population's universe estimates and then claim to have accurate and unbiased estimates for that general population. Absent any other proof, we find this to be an unsubstantiated claim. Here is the simplest test that we can construct --- if we commission someone to conduct an internet survey of the incidence of internet usage, they can weight that sample any which way they want and the result would still be ... 100%, and quite wrong at that!
We now offer an empirical test of the representativeness of an internet survey. Within the MARS 2002 survey, there is a simple random sample of 7,293 adults in the USA. To compensate for the incompleteness of the coverage of the sampling frame and the differential response rates by population subgroups, that sample was weighted to US census figures on demographic characteristics such as age, sex, education, occupation, personal income, household income, geography, household size, race, ethnicity, etc. This is classical post-stratification weighting used by most survey organizations. Then, audiences estimates were obtained for 96 consumer magazine titles.
Next, we took the subset of 4,632 adults in the MARS sample who had used the internet in the last 30 days and we weighted them to the same US census figures in exactly the same way. Thus, this sample will match the full sample on the same demographic characteristics such as age, sex, education, occupation, personal income, household income, geographical, household size, race, ethnicity, etc. Then, audience estimates were obtained for the same 96 consumer magazine titles. Here, we are assuming that conducting the same survey using a different survey mode on the same set of persons will yield identical responses. This is known NOT to be true, but we will gloss over issues of survey mode differences in this discussion.
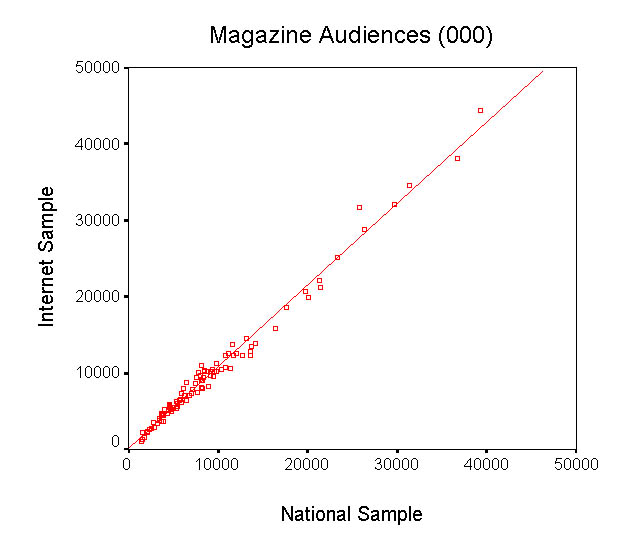
In the next chart, we present the two sets of magazine audiences in the form of scatterplot. It would appear that the two series are highly correlated. Indeed, the correlation coefficient is a very high 0.993 (where 1.000 represents perfection). In this scatterplot, we have also plotted the best fitting straight line. If we look at that line carefully, we would realize that it lies above the 45 degree diagonal line (which represents perfection). The fact that the line lies above the 45 degree line means that the Internet-based audience estimates tend to be higher.
(source: 2002 MARS study)
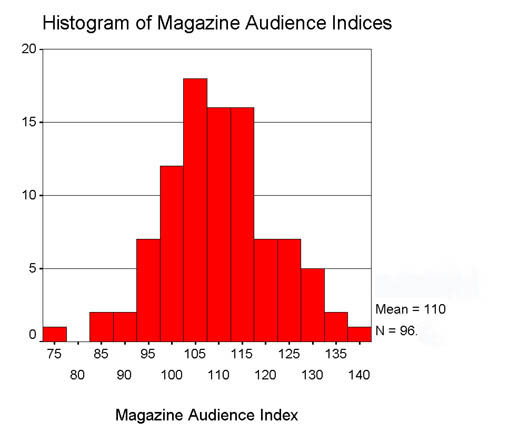
We can look at the numbers in another way. For each magazine title, we define a magazine audience index as 100 times the internet-based estimates divided by the general population estimate. An index of 100 would represent perfection. An index greater than 100 implies a larger internet estimates and vice versa. In the next chart, we show a histogram of the distrubtion of the 96 magazine audience indices. The average index is 110, which means that the internet-based magazine audience estimates are 10% high on the average. This overestimate is not consistent across the magazine titles, as some are significantly higher and some are significantly lower. The differences are sufficiently large that they would be unacceptable for the purpose of media planning (that is, some magazine would be advantaged by 40% while another would be disadvantaged by 25%).
(source: 2002 MARS study)
This is not say that we have proclaimed the internet to be totally useless for magazine audience estimation. It is certainly useful, and in fact quite natural, for measuring magazine readership among internet users. In the case for professional technology magazines, for example. And as more people get on the internet, it will be a better approximant of the general population. It is also possible that certain types of data adjustments to the internet-based survey estimates may yield accurate estimates for the general population. But these data adjustments will require some knowledge about the relationship between non-internet usage and the survey outcome variables and such relationships cannot be revealed solely on the basis of an internet-based survey.
We should point out that, in this article, we have not even remotely hinted at the difficulty of obtaining a sample that is representative of the internet. There is no universal frame for internet users. As a result, an internet survey sample is often assembled from pop-up intercepts at selected cooperating websites or permission-based emails, which incur an unknown degree of bias.
(posted by Roland Soong on 04/07/2003)
(Return to Zona Latina's Home Page)