Data Fusion in Latin America
(This article is based upon a talk given by Roland Soong at the 47th Annual Conference of the Advertising Research Foundation, New York City on March 7, 2001. The reader is warned that this article is highly technical in nature.)
What
is data fusion?
In
the field of media research, there are studies that collect detailed information
in various areas. Here are some
examples:
Television people meter panels that collect minute-by-minute television tuning/viewing data to all channels
Radio
surveys that collect radio listening behavior using diaries or telephone
Internet
user panels that collect detailed web usage
Consumer
surveys that collect information on multimedia usage and product consumption
As
much as it is desirable to collect all this information from a single group of
people, the many historical experiments across the world suggest that it is too
burdensome on people. Nobody is expected
to push buttons for television viewing, record diaries for radio listening,
answer questions about reading and fill out 100 page product usage booklets for
any length of time. Nevertheless, for many reasons, it is
necessary to correlate various types of data across databases. Data
fusion is the process whereby two or more of these databases are integrated into
a single source database which contains information from the individual databases.
The
databases that are fused could be about virtually any subject.
Here are some examples of data fusion projects from all over the world:
Belgium Tax Returns/Panel Study of Belgian Households
Canadian Print Measurement Bureau/Bureau of Broadcast Measurement
Canadian Social Policy Simulation Database
Canadian Survey of Consumer Finances/Family Expenditure Survey
Dutch National Services & Amenities Utilization Survey
German Media Research (AG.GA)
Italian ISPIPRESS surveys of magazine and newspaper readership
Italian Survey on Consumption/Bank of Italy Survey on Income & Wealth
Japanese Family Income & Expenditure Survey/Family Savings Survey
New Zealand ACNielsen Panorama service
Norwegian Population Census
Spanish Household Survey/Income Tax File
United Kingdom Broadcasters' Audience Research Board/National Readership Survey
United Kingdom Family Resources Survey/Family Expenditure Survey
US Current Population Survey/American Housing Survey
US Health Interview Survey/Survey of Income and Education
US Institute of Taxation & Economic Policy Tax Model
US National Longitudinal Survey of Youth/Maternal and Infant Health Survey
US Survey of Income and Program Participation/Medical Expenses Panel Survey
US Tax Model/Survey of Financial Characteristics of Consumers
Data fusion in the Americas
The subject of this paper will be some of the data fusion projects that are going on or about to commence in media research in Latin America. In the countries of Argentina, Brazil and Mexico, IBOPE Media Information operates television people meter panels. In these same countries, Kantar Media Research, in conjunction with local partners, conducts the multimedia/product usage study known as TGI (Target Group Index). Currently in each of these three Latin American countries, the two databases are being fused into single source databases.
The demand for data fusion is driven primarily by two needs:
(1) Target Group Ratings: The television people meter panels (referred to by the acronym TAM for Television Audience Measurement) provide detailed minute-by-minute television viewing data which can be filtered by geography, age, sex and socio-economic level. The use of such demographics may result in some inefficiency in media planning because of misidentification of the target groups (for an illustrated example, see Defining Target Groups in Media Planning). The consumer studies (referred to by the acronym TGI for Target Group Index) contain detailed product/service usage for hundreds of categories (such as cinema attendance, business travel, baby pampers, breakfast cereals, automobile purchase, etc) but only crude television viewing information. A successfully fused database will provide detailed television ratings for these product/service users. Such ratings are known as Target Group Ratings (TGR).
(2) Multimedia Optimization: Currently, there exists a number of highly sophisticated software optimizers that will produce optimal advertising schedules for various criteria. For example, the software programs SuperMidas and X*pert are available for various television people meter databases; separate software programs are available for print media optimization. In real life, many advertising schedules will involve multimedia elements (television, radio, newspapers, magazines, outdoor, internet, cinema, etc). Currently, the evaluation of such multimedia advertising schedules are assembled by a combination of indirect estimation and subjective opinion. A successfully fused database will provide a means of optimizing multimedia advertising schedules if the suitable software is available.
As
a historical note, we note that the two corresponding studies in the United
States of America --- the Nielsen Television Index produced by Nielsen Media
Research and the National Study of Mediamark Research Inc --- have not been
fused yet. At least in this aspect, Latin America has proved to be more
progressive.
One is limited by the availability of common variables. After all, one cannot match on what is not known.
One is limited by the predictive power of the common variables. Generally, most studies will collect information about standard demographics such as geography, age, sex and socio-economic level. Fortunately, these demographics are strong correlates with media behavior and product/service usage (for otherwise they would not have been collected in the first place).
One is limited by the compatibility of the variables from different surveys. For example, TAM contains precise television viewing information across any configuration of time period and station, while TGI contains self-reported information for broad time periods, limited television programs and station totals. Even a simple comparison of overall levels would show that the TAM data are quantitatively different from the TGI data. Thus, one should not use the TAM total viewing minutes to match against the TGI self-reported amount of viewing.
One is limited by the sample design features of the databases. Technical issues such as sample sizes, sample allocation, respondent selection and question phrasing can have a drastic effect on the data fusion.
The general idea behind statistical matching is that for each respondent in one database, we wish to find the best matching person (or persons) in the other database. Ideally, we would like to be able to successfully match on all the common variables (for example, same city, same socio-economic level, same sex, same exact age, same educational level, same occupation, same pay television status, same number of television sets, etc). In practice, there may be no perfect matching person out there, and we will have to accept some person (or persons ) matching on just some (but not all) of the common variables.
Importance Weighting
Suppose we have ten common variables and there is nobody that matches this respondent on all ten. Instead, there is one person who matches on nine common variables, and another person who matches also on nine common variables (but not the same nine). What gives? We recognize that not all common variables are equal, because some are more important than others and our decision will depend on how important are those variables that were matched. The importance of a common variable may be due to
(1) The relevance of the common variable in the fused database. For example, if the purpose is to fuse infant products (such as disposable diapers) with the television ratings, then the presence of infant should be designated as the most important matching variable above all else, whereas the size of television screen in the living room should count for much less.
(2) The specific requirements from users. For example, if a separate sub-database is to be issued to certain users (such as Mexico City-only users, or cable/satellite homes only), then the defining variables should be matched exactly.
(3) The contribution of the common variable towards the performance of the fusion. This can be quantified in a number of different ways, and we will describe some of these measures later.
Here is an example of a scoring algorithm that assigns importance weights to the common variables
- Always the same geographical region
- Always the same gender
- Always the same pay tv status
- Assign zero points initially to any matching candidate so far
- Add 16 points if in same age group
- Add 16 points if in same socio-economic level
- Add 12 points if same household head status
- Add 12 points if same housewife status
- Add 8 points if same presence of children status
- Add 2 points if same multi tv set status
- Add 1 point if same telephone status
The best match will be the person (or persons) with the highest score among the potential candidates.
Deriving and Evaluating Importance Weights
The previous example of a set of importance weights had been suggested by an experienced user of the TAM and TGI data. That was a subjective opinion, and another person may come up with a different scheme. It may also be less than optimal. We will now describe a large-scale numerical experiment in which we attempted to derive the optimal set of importance weights for a particular country.
To start, we have to be able to gauge the performance of a set of importance weights within the fusion algorithm. The procedure is as follows:
( Technical digression: The accuracy statistic should be used with caution because it depends on the incidence level. We can demonstrate this with a couple of examples. Suppose that a variable has incidence of 1% in the donor as well as the recipient samples. After the split-sample fusion, we would expect about the fused incidence in the recipient sample to be about 1% too. The perfect fusion would have yielded 100% accuracy. The worst possible fusion would have missed the 1% original people altogether and fused the data onto the wrong 1%, and yet its accuracy would be 98%. Next, suppose that another variable has incidence of 50% in the donor as well as the recipient samples. After the split-sample fusion, we would expect the fused incidence to be about 50% in the recipient sample. The perfect fusion would have yielded 100% accuracy, the worst fusion would have 0% accuracy and a fusion with 98% accuracy would be considered to be very good. For this reason, the accuracy statistic should not be compared across different datasets (such as comparing fusion in one country against that in another country, or comparing magazine data against product consumption because any difference may be due to incidence levels and not the goodness of the fusions). But the accuracy statistic can certainly be used for comparing different fusion algorithms and different sets of importance weights for the same variables in the same database.
So what is the set of importance weights that would generate the highest accuracy rate? Unfortunately, there is no direct close-formed method of obtaining the answer. So we ran a numerical experiment using a genetic algorithm. This a method of evolutionary computation that draws on the Darwinian principles of natural selection to evolve better and better solutions for otherwise intractable optimization problems (for an introduction to this subject, see the website GeneticAlgorithms.com). Among many types of applications, the genetic algorithm approach has been used to optimize press schedules. The procedure is summarized as follows:
We will now report the results from our numerical experiment for fusing 270 demographic/product variables on 10 common variables in Mexico. During the course of our experiment, we generated a total of 1054 sets of importance weights. From this very large set of importance weights, we obtained these accuracy rates:
In a nutshell, importance weights do not seem to have a material impact on the accuracy. This is not necessarily an unexpected outcome. In the literature of statistics (and allied disciplines such as artificial intelligence), this phenomenon is known as the "flat maximum effect" or the "curse of insensitivity." To put it in layman's terms, any non-trivial assignment of importance weights in any fusion algorithm should recognize that someone who matches on all 10 variables is better than someone who matches on only 3 out of 10 variables.
The implication is that, for some configurations of datasets and common variables, the choice of importance weights and fusion algorithms may make little difference. Please note that we were careful to add a qualifier because things may be different in other situations. In the present case, we happened to have only 10 common variables and we were able to achieve high matching successes within these samples of about 11,000 TGI respondents and 8,000 TAM respondents. In another situation, we may have a sudden wealth of hundreds of common variables which cannot all be matched, so that the judicious choice of a good subset will become important. But we are willing to bet that our experienced user will probably still be able to pick a set of importance weights that would be close to the best solution found by the genetic algorithm.
Description of Fusion Algorithm
There are in fact many possible statistical matching algorithms, based upon importance weights, distance measures and matching methods. We have experimented with various statistical matching algorithms, but the results from those many experiments would be too much material to present here. The algorithm that we finally chose is a constrained statistical matching algorithm that has its genesis in the field of operations research.
In operations research, a well-known problem is the transportation problem --- how to ship the supply stored in m warehouses to meet the demand from n retail stores with minimum total shipping cost. This problem was formulated in the late 1940's and the standard algorithm (known as the stepping stone algorithm) was presented in the 1950's. Today, this algorithm is in fact included in the coursework of many quantitative Masters of Business Administration programs because of its practical utility and mathematical elegance.
In the context of data fusion, the transportation problem is recast as follows: how to ship m TGI respondents to n TAM respondents, with their case weights representing supply and demand respectively, and the shipping cost equals the badness of fit between individual persons. This is a well-formulated problem whose solution is known. For our purposes, the three most important properties of this fusion algorithm are:
Property #1: Preservation of all TAM data
All TAM respondents appear in the fused database with their original case weights and all their TAM data. By definition, all TAM data are preserved, in that there is no difference in the television ratings from the original TAM database with those in the fused database. This means that all derived statistics --- gross ratings points, gross impressions, duplication, reach, frequency, turnover, exclusive cumes --- are preserved exactly.
Property #2: Preservation of all TGI data
All TGI respondents appear in the fused database with approximately the same original case weights and all their TGI data. Since the case weights are approximately preserved, the TGI data will be also be approximately preserved. The reason why the TGI data are not perfectly preserved is the result of some minor accounting discrepancies (e.g. the projected TAM universe is for persons 4+ in television households, while the projected TGI universe is for persons 12-64 years old in all households, such that they may not have the same projected totals to the new universe of persons 12-64 years in television households and any discrepancy is resolved in favor of the TAM database).
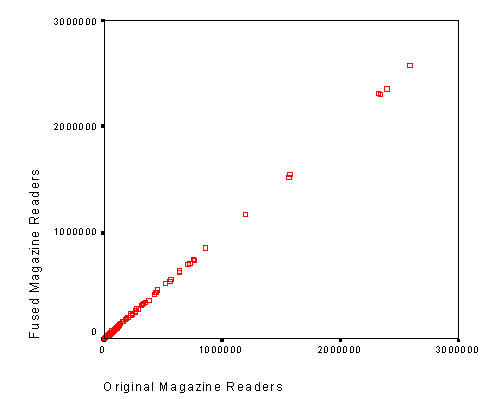
In any case, the discrepancies between the original and fused TGI data are very small. For example, in the case of Mexico, the average discrepancy between the original and fused magazine audiences is 2 parts out of 1000. In practical terms, for example, if a magazine has a total audience of 1,000,000 originally, it may have 1,002,000 instead in the fused database; and if you had paid $10000 for an ad, your cost per thousand would have gone from $10/M to $9.98/M. The graph below shows a comparison of the original versus the fused readers for the 98 measured magazines in Mexico. It is fair to say the distortions are fairly minor, especially when we consider the sizes of the standard errors that are associated with the estimates.
For a fused database that will be used in multimedia optimization, the preservation of the media currencies (both television and print) is extremely important. The fact that our fusion algorithm achieves this goal is the major reason that we chose it.
Property #3: Relationship between TAM and TGI data
The goodness of fit of the relationship between the TAM and TGI data cannot be gauged directly with these two datasets since we fused these databases precisely due to the absence of the information. There is also no external single source database to serve as a benchmark. Therefore, the relationship between the TAM and TGI must be inferred indirectly. As it happens, the TGI database contains a number of television variables (such as time periods and program types). While these variables are not as quantitatively precise as the TAM data, they do have the same general qualitative characteristics (e.g. housewives watch relatively more telenovelas, etc) and may be used as surrogate variables.
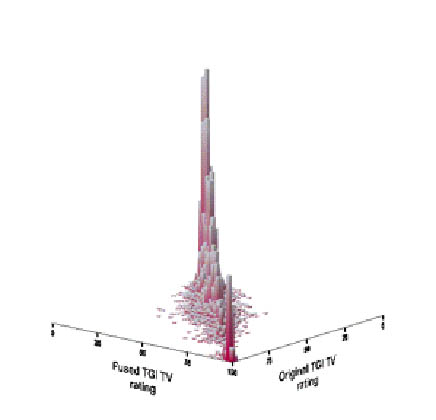
For our purposes here, we took the TGI sample and split it randomly into two halves. Then we fused one of the halves onto the other half. For each half sample, we computed the original television 'ratings' separately for all the TGI categories (e.g. the percent of cellular telephone owners who watch televised sports programs regularly). Then we computed the fused television 'ratings' for these same TGI categories.
The next graph is a comparison of the original versus fused data of 54 TGI television 'ratings' among 271 TGI demographic/product usage categories in Mexico. The bulk of these 'ratings' fall firmly along the diagonal, showing that the fused results are close to the originals.
In addition to those three properties above, we have a suite of other criteria that we used to evaluate fusion algorithms. We do not have the time today to provide a detailed discussion, so we have present a brief summary.
Some Reflections on Data Fusion
Obviously, we consider these data fusion projects in Latin America to be successful ones in terms of their outcomes. Whereas most discussions about data fusion seem to drift around the subject of fusion algorithms, we believe their relative importance is overstated. In our experience, just as important are other issues:
For those people who are attempting to organize data fusion elsewhere, we have to emphasize the importance of the organizational factors for these data fusion projects to materialize in Latin America. IBOPE Media Information/Kantar Media Research are the stakeholders in the TAM and TGI services. There are no conflicts of interest as might be the case if the two studies are owned by different companies who represent different constituencies with different interests. The commercial needs for data fusion are also quite clear at the outset for we would never have bothered to do the project. Finally, the two companies were open-minded about the viability of the data fusion project, and were willing to invest in the research-and-development efforts to make these projects a reality.
At a personal level, after a career with stints in radio, television, print, multinational and internet research, I must say that data fusion is the single most interesting and challenging subject that I have come across. Data fusion is like the core of a grand unification theory, with deep connections to many different branches of science. Let me read you a list of topics --- ADAboost, primal/dual simplex algorithm, Mahalanobis distance, record linkage, head injury patients, stacked generalization, unimodularity, multiple imputation, support vector machines, k-nearest neighbors, pattern classification, kinship censuses, quadratic discrimination, Fatal Accident Reporting system, NP-completeness, stochastic relaxation, the Hungarian method, quadratic programming, radiologic imaging, National Death Index, receiver operating characteristic, large margin classifiers, medical diagnostic systems, Fellegi-Sunter model, ... Are you intrigued? You can check out the huge bibliography at the bottom of this page.
![]()
DATA FUSION BIBLIOGRAPHY
(Return to Zona Latina's Home Page)